
Pi节点区块延迟的原因
 Admin
AdminPi节点是一个点对点网络(peer-to-peer,P2P),节点通过「单向广播」传递TRANSACTION及SCP_MESSAGE讯息。
如下图所示,你的节点如何得知最新的区块信息,可能有很多条路径。
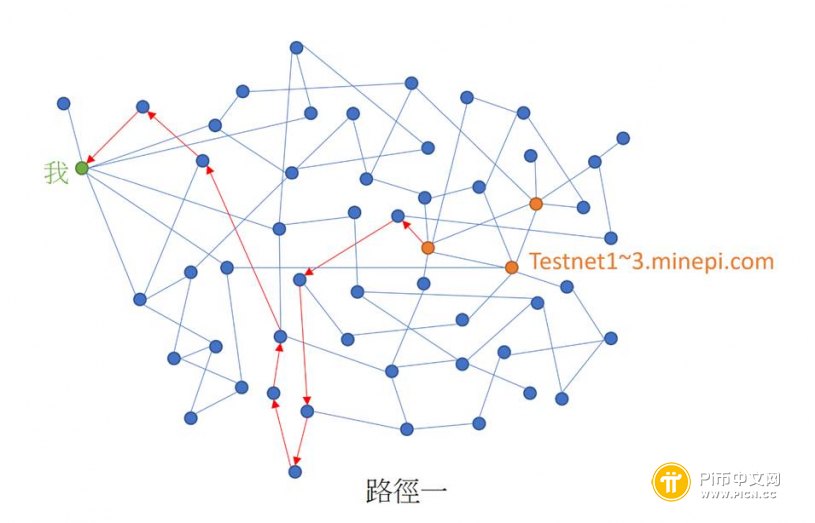

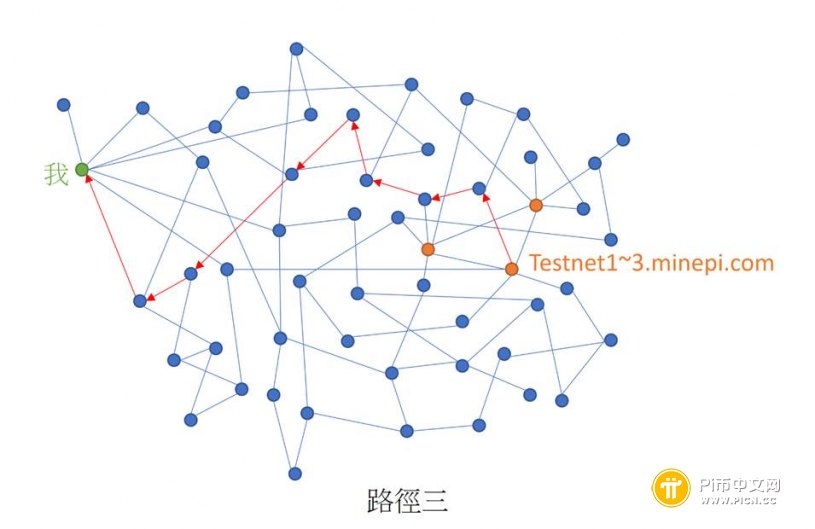
当执行
docker exec -it pi-consensus stellar-core http-command info
将输出如下结果:
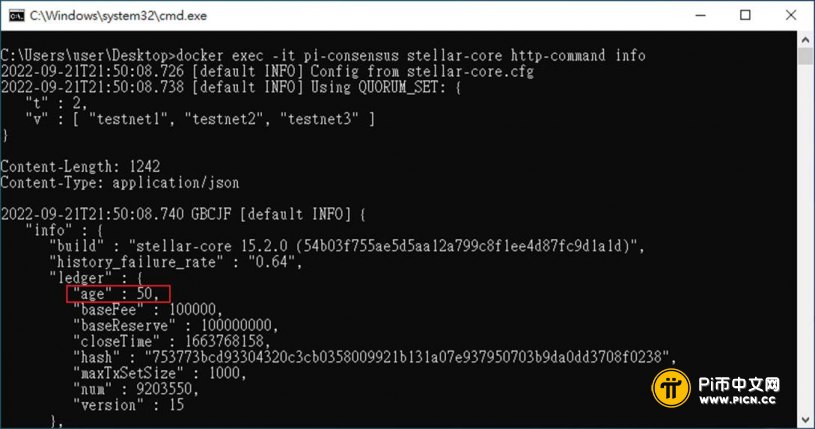
ledger的age是本地账本(区块)自关闭以来经过的时间,在正常形况下应少于10秒。
你也可以从%appdata%\Pi Network\docker_volumes\supervisor_logs\stellar-core-stdout---supervisor-xxx_.log中发现,大约5~6秒就会关闭一个区块。

但如果你多检查几次,发现age一直增加,你会在log看到「[Herder WARNING] Ledger took xxx seconds」讯息,前后区块关闭的间隔时间很长, 但后面的区块时间却都挤在一起,因为数据有所延迟,是后来才一口气收到。
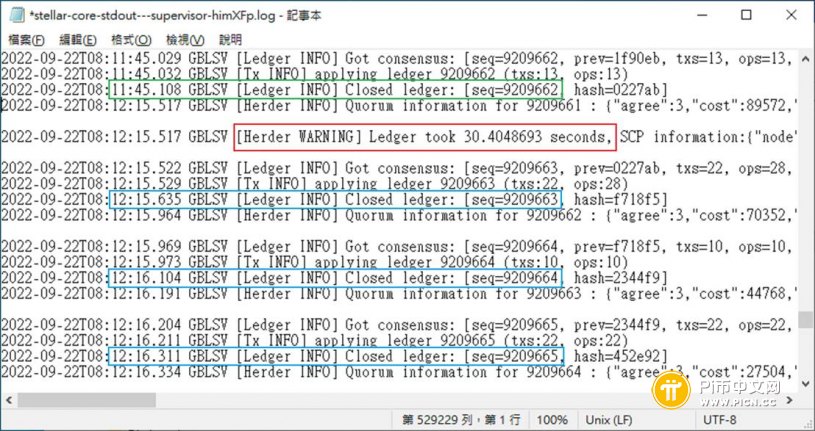
甚至延迟时间再长一点,还会有「[Herder WARNING] Lost track of consensus」、「[Herder WARNING] Out of sync context讯息。
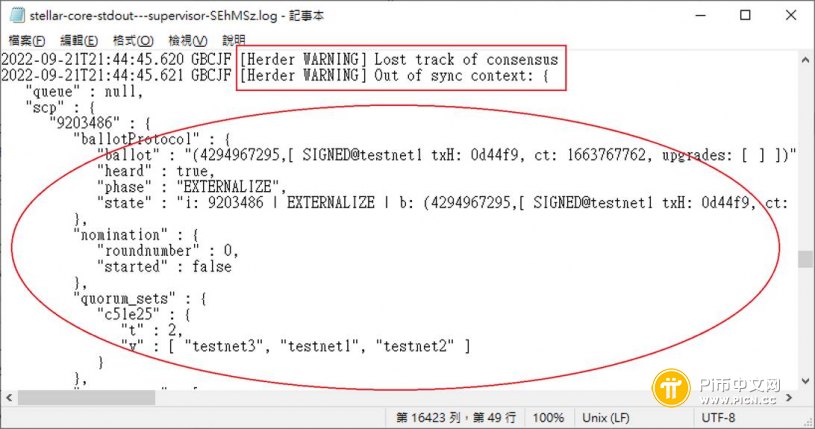
若超过1分钟就会进入Catching up的状态了。

除了极少数是真的因为你的设备或网络有问题,大部分就是运气不好,如一开头所讲的,在这个P2P网络中,你无法控制数据如何传递。
怎么办? 不需要怎么办,这是一个正常现象,你无法改善全世界的网络,而且也跟节点奖励无关。
但如果你真的很龟毛,实在是受不鸟,可以试试连接其他节点,“也许”状况能好一点。
先执行
docker exec -it pi-consensus stellar-core http-command peers?fullkeys=true
查出目前连接的节点。
结果如下,可看到inbound及outbound两部分,还有每个节点的id。
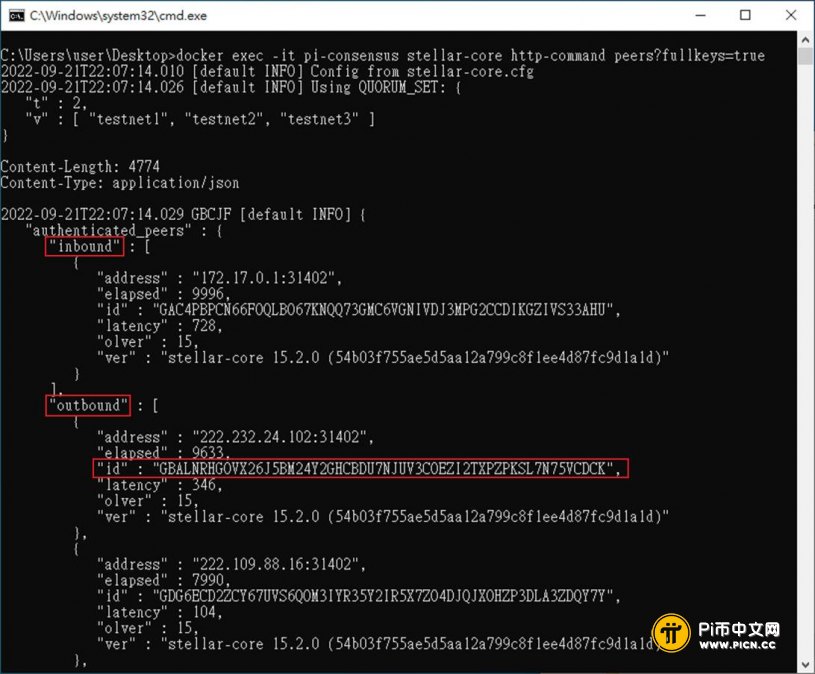
挑一个你看不顺眼的,比如latency特别高的,用
docker exec -it pi-consensus stellar-core http-command droppeer?node="xxx"
指令删掉它。
xxx就填刚刚查出来的节点id。
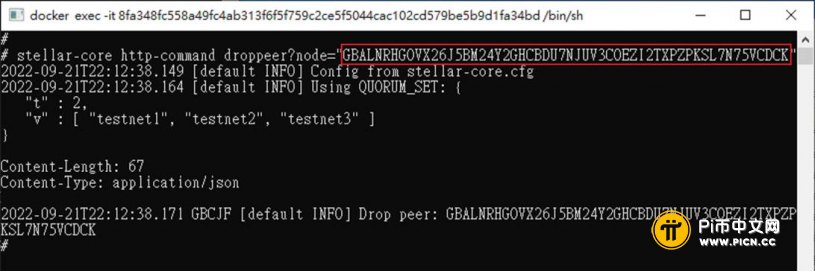
如果你删掉的是一个outbound连线,你的节点马上就会再重新连上另一个节点; 但如果你删的是inbound连线,就看运气了,不见得立刻会有人连进来。
换掉几个节点,看看区块同步会不会比较顺畅。但真的没必要。
另外,根据观察,节点连线数量越多,发生区块延迟的机会越小,因为你的节点有更多不同路径可以收到广播讯息。 然而因为outbound连线数量的上限是8,通常都是满的,所以能增加的连线数就剩inbound了。 这就容易引起一个误解,因为我的网络很稳定(这里的稳定是指区块都没有延,这也是误解),所以inbound连线一直增加。 事实上正好相反,因为inbound连线数增加,所以区块都没有延迟。
本文来源:yuanrui919 版权归原作者所有,转载请保留出处。本站文章发布于 2022-08-18
温馨提示:文章内容系作者个人观点,不代表 Pi币中文网 对其观点赞同或支持。




还没有评论,来说两句吧...